How to Build AI Development Team: Opportunities and Common Pitfalls
- Updated: Jun 15, 2026
- 19 min

CEO
If you’ve been thinking about bringing AI into your business, you’ve probably already run into the first problem: there’s a lot of information out there about what AI can do, and very little about what it takes to build a team around it.
What roles do you need? How much should you budget? Do you hire people or work with an external team? And what are the things that tend to go wrong that nobody warns you about upfront?
That’s exactly what I want to cover here. I’ve been through this with different companies when building AI-powered solutions for startups and established companies.
Some clients are at the start of their AI journey, just figuring out their first use case. Others come trying to understand why the AI initiatives they invested in didn’t deliver the business outcomes they expected. What we’ve learned from that work is what I’m sharing here.
One honest note before I start: this won’t tell you what’s universally best, because that doesn’t exist. What it will do is help you ask better questions, and in early-stage AI projects, that’s often the most valuable thing you can have.
We've helped teams navigate the tricky parts — from hiring to execution.
TL;DR
- Build only when the problem is defined. A dedicated AI team makes sense when you have a specific, painful, high-frequency problem and the data to support it.
- Choose your path before you hire. API integration (OpenAI, Anthropic, Gemini via RAG or similar) is the right starting point for most companies.
- The minimum viable team for an API-path MVP is an ML Engineer, a Data Engineer, and an AI-focused PM. Everything else scales in as the product matures.
- Outsource to validate, build in-house or hybrid to scale. An external team can get you in front of real users in 2–3 months. Assembling an internal team takes four to six months before anyone is productive.
- Data readiness matters more than machine learning model choice. If your internal data isn’t clean, accessible, and structured correctly, no model will save you. The Data Engineer is often the most important early hire.
- Infrastructure costs will surprise you. API token costs, compute, and vector storage can exceed team costs at scale. Model this before you finalize your architecture.
- The pitfalls that kill projects are hiring on credentials over practical ability, skipping QA specific to AI systems, treating deployment as the finish line, and underestimating compliance in regulated industries.
When Does a Dedicated AI Team Make Sense?
Hiring developers for AI project before you’ve defined the problem is how you end up with a talented team solving the wrong thing.
AI development only delivers real business value when it’s grounded in a business context: the specific problem, the data behind it, and a clear definition of success. That’s especially true for companies mid-digital transformation, where AI can either accelerate progress or become an expensive distraction.
Before reaching out to agencies, it’s worth sitting down and answering these three questions:
- What specific problem are we solving? Actual user pain, business inefficiency, or missed opportunity you are targeting.
- What data do we already have? AI models run on data. If the data doesn’t exist, isn’t clean, or isn’t accessible, that shapes everything, including who you need to hire first.
- What does success look like in our case? A measurable outcome. “Support ticket volume drops 30%” or “time-to-hire reduces by two weeks” are good examples of measurable metrics.
At SpdLoad, when we start working with a new client on an AI product, we usually begin with scoping. For example, when we’ve been working on this RAG Knowledge Copilot for enterprises, the first thing we did was map where the actual pain was.
In this case, the client’s employees were losing hours searching for answers across shared drives and outdated documents. It often happened that different departments were explaining the same policies in different ways. And senior employees were getting pulled into questions that shouldn’t have reached them at all.
That scoping work determined the architecture, the role-aware access structure, and the decision to ground every response in source documents to eliminate hallucinations entirely. None of those decisions came from technical preference. They came directly from understanding the problem first.
But before even reaching out ot us, the client was hesitating between a custom-built AI and an off-the-shelf one. So I think I need to address this one as well.
API Integration vs. Custom Model Development: Which Path Are You On?
There are essentially two paths for building AI into a product:
| API integration path | Custom model path | |
|---|---|---|
| What it means | Using existing models (OpenAI, Anthropic, Gemini) via API, often with architectures like RAG | Building and training your own model from scratch or fine-tuning it heavily |
| Who it’s for | Most startups, B2B products, MVPs, and internal tools | Companies with unique data, strict regulatory needs, or performance gaps that off-the-shelf solutions can’t close |
| Team you need | Strong backend engineers, prompt engineering skills, data flow architecture | Data scientists, research engineers, and significant data infrastructure |
| Time to first value | Weeks to a few months | Many months to over a year |
| Typical cost | Significantly lower | Significantly higher — compute, talent, and time |
For most early-stage products, the API path is the appropriate choice.
The custom model conversation makes sense when you have a genuine reason for it:
- Proprietary data that gives you a real competitive edge.
- Regulatory constraints that prevent sending data to third-party APIs.
- Performance requirements that existing models genuinely can’t meet.
This path also involves significant data collection work upfront — you need sufficient labeled examples from the right data sources before model training can produce anything reliable, which adds months before you see results.
Outside of those situations, building your own model usually solves a problem you don’t yet have, at the cost of time and money you can’t easily recover. A non-technical founder who hires a data science research team for what is essentially an API integration problem can easily spend six figures more than necessary, and still wonder six months later why nothing has shipped. Here, we talk more about custom AI vs off-the-shelf solutions.
Once you know what you’re actually building, and roughly how, you’re ready to think about who you need.
The Core Roles on an AI Engineering Team
Lack of expertise is one of the top reasons that slow adoption of generative AI across organizations, according to the survey from Bain & Company.
A lot of engineering teams either over-hire (bringing in expensive specialists too early) or under-hire (assuming one generalist can cover everything). Neither works well.
The right team structures depend entirely on what you’re building and where you are in the process. There’s no universal template, only specialized skills that map to specific problems.
Here’s a practical breakdown of the core roles to be aware of when building an AI engineering team.
ML Engineer / AI Engineer: The Builder
This is the person who takes a model and turns it into something that works inside your product. They write the code, build the pipelines, integrate the APIs, and make sure the AI feature behaves reliably under real conditions.
In modern AI dev team setups, this often includes working alongside coding agent tools that assist with generating code, running unit tests, and accelerating the development workflow, but the engineer still owns the architectural decisions and judges the quality of what gets shipped.
A common misconception is that ML Engineers and Data Scientists are the same thing. They’re not. A machine learning engineer is closer to a software engineer who specializes in AI systems. They care about deployment, latency, reliability, and integration, not just model accuracy. For most API-path products, this is the first hire to consider.
Data Engineer: The Foundation
No matter how good your model is, it will only be as useful as the data feeding it. Data Engineers build and maintain the reliable data pipelines that collect, clean, and organize the data. This is the foundation of your data infrastructure, and data quality problems here will surface as model problems later, often in ways that are hard to diagnose.
This role often gets deprioritized because it’s invisible when it works. But it becomes very visible when it doesn’t, usually when a model starts producing outputs that don’t make sense, and the culprit turns out to be messy, inconsistent, or incomplete data upstream. If your use case depends on internal company data, a Data Engineer needs to be an early priority.
Data Scientist / Research Engineer: The Thinker
This role is more experimental by nature. Data Scientists explore data, test hypotheses, evaluate model behavior, and help the team understand what’s actually happening inside the system. They build and validate data science models, and bring deep expertise in statistical reasoning that the rest of the team typically doesn’t have.
They’re most valuable when you’re doing original AI research, working with complex or novel datasets, or trying to push past what standard models can offer out of the box. For teams on the API integration path, a full-time Data Scientist is often premature at the MVP stage. The need grows as the product matures and the questions get harder.
Product Manager (AI-Focused): The Connector
An AI-focused PM does something genuinely difficult: they translate what’s technically possible into what’s actually worth building.
They work closely with engineers to understand constraints, and closely with users to understand needs, and they hold both at the same time. In practice, this means owning user stories and acceptance criteria that reflect actual business needs, not just technical capabilities.
Think of this role as the product owner who sits between the AI dev team and the business. Similar to what business analysts traditionally do, but with enough technical fluency to engage meaningfully on model behavior and constraints.
What makes this role distinct from a standard PM is comfort with ambiguity. AI products behave probabilistically. Outputs vary. Edge cases are unpredictable. A good AI PM doesn’t expect certainty they build processes that handle uncertainty gracefully.
Without this role, technical teams often build impressive things that don’t quite fit the problem. With it, the gap between “working model” and “useful product” closes much faster.
MLOps / AI Infrastructure Engineer: The One Who Keeps It Running
This role tends to be underestimated until something breaks in production. MLOps engineers handle the infrastructure that keeps AI systems stable, scalable, and observable — model deployment, monitoring, versioning, and the processes that let teams update models without breaking everything downstream.
For early MVPs, some of this work can be handled by a skilled ML Engineer. As usage scales, a dedicated MLOps function becomes genuinely important.
AI QA Engineer / LLM Evaluator: The One Who Keeps It Honest
This is the role most teams add too late, and the omission is usually invisible until a user finds the failure.
Traditional QA checks whether buttons work and forms submit: a test suite of unit tests and test scenarios that verify working code behaves as expected. AI systems need a fundamentally different layer on top of that. You can’t write a test that says “the model will always return X.”
Outputs are probabilistic. Edge cases are infinite. The failure modes are different, including hallucinations, inconsistent tone, retrieval errors, and degraded accuracy on specific query types. Critically, you’re not just testing the code, you’re also evaluating the agent’s output against real user needs, which requires critical thinking about what “correct” even means in a given context.
Domain Expert: The Context Layer
In industries like healthcare, HR, and fintech, having someone who deeply understands the space the AI is serving can be the difference between a product that technically works and one that’s actually appropriate for real use.
This might be a practicing clinician, a compliance officer, or an AI strategist with domain expertise who bridges the technical and business sides. What matters is their deep understanding of how the domain actually works in the messy reality of how people use systems under real conditions.What this role does:
- Tracks hallucination rates and flags edge case failures
- Evaluates retrieval quality and context accuracy for RAG-based systems
- Builds and maintains evaluation frameworks that run continuously, not just at launch
- Monitors for model drift over time
For teams building on RAG architectures, especially, this function is what keeps user trust intact.
| Role | Primary value | When you need them |
|---|---|---|
| ML / AI Engineer | Builds and integrates AI features | From the start |
| Data Engineer | Keeps data clean and accessible | Early, especially with internal data |
| Data Scientist | Research, experimentation, analysis | As complexity grows |
| AI Product Manager | Bridges tech and user needs | From the start |
| MLOps Engineer | Infrastructure, stability, monitoring | Before you scale |
| AI QA / LLM Evaluator | Catches what traditional testing misses | Earlier than most teams think |
| Domain Expert | Industry context and compliance | Whenever the domain has real stakes |
Not every team needs all of these roles from day one. A focused MVP might start with an ML Engineer, a Data Engineer, and a PM who’s comfortable with AI.
AI Development Team: In-House, Outsource, or Hybrid?
Building an internal AI team is expensive and always takes longer than you’ve expected.
From my experience, it might take around:
- 4–8 weeks to find and interview candidates.
- Another 2–4 weeks for offers, negotiations, and notice periods.
- 2–4 weeks of onboarding before anyone is truly productive.
That’s potentially four to six months before your team starts shipping. For a company trying to validate an AI use case, that’s a long time to wait on a hypothesis that might not hold.
I think that the in-house path makes more sense after you’ve proven that the concept works, not as the vehicle for proving it.
Outsourcing an AI Development Team
A well-scoped AI MVP built with an experienced external team can be in front of real users in 2–3 months. That means real feedback, real usage data, and a much clearer picture of whether the investment in an internal team is justified and what that team should actually be built to do.
The questions worth asking when evaluating potential outsourced companies for further collaboration:
- Have they built AI products in your domain before, or just adjacent to it?
- Can they show you how they handle the entire software development lifecycle, including the project discovery, evaluation, testing, etc.
- What does knowledge transfer look like at the end of the engagement?
- Who owns the IP, and is that clearly documented upfront?
That last point matters more than founders may think. IP ownership, data handling practices, and what happens when the engagement ends should be defined before work begins. That’s our common practice at SpdLoad and what I would recommend to everyone who’s working with AI experts.
The Hybrid Model: A Golden Middle
Here, you get the best of both worlds.
What works in the hybrid model is having a small core internal team structure (project managers and a couple of engineers who really know the product), then bringing in outside specialists when you need specific skills or extra hands.
Unlike traditional teams, where everyone is in one place under one org chart, this is a team-based approach that requires deliberate cross-functional collaboration to work. The coordination overhead is real, but so is the flexibility.
Why does this work so well? A few reasons:
- Internal team maintains continuity and product context.
- You can bring in outside expertise without going through months of hiring.
- Knowledge gets shared bit by bit instead of dumping everything at the end.
The downside? It can be a pain to coordinate between teams. When you’ve got two teams working on the same thing, you need really good communication, clear boundaries about who owns what, and someone internal who actually understands the tech well enough to stay in sync.
| Situation | Suggested path |
|---|---|
| Unvalidated concept, limited runway | Outsource to validate fast |
| Proven concept, scaling a known product | Build in-house or hybrid |
| Specific expertise gap in existing team | Hybrid — augment, don’t replace |
| Long-term AI as core product differentiator | Invest in internal capability over time |
| Compliance-heavy domain (health, fintech) | Ensure any external partner has domain experience |
At SpdLoad, we work with companies at different points on this spectrum. Some come to us to build and validate their MVP before they’ve hired anyone internally. Others have an internal team and bring us in for specific capabilities, like infrastructure, evaluation frameworks, or a particular integration.
The structure matters less than the clarity around who owns what and what success looks like at each stage.
IP, AI Governance, and What to Define Before Work Begins
This gets skipped in most hiring guides. It shouldn’t.
“You own the code” is not sufficient when working with an external AI development partner. A proper contract needs to address ownership of several distinct things: the model weights (if you fine-tune a model, who owns those weights?); the training data used and whether any third-party data introduces licensing obligations; custom evaluation frameworks and tooling built during the engagement; and the outputs the system generates in production.
For internal hires, make sure your employment agreements cover AI-specific IP, particularly if engineers are fine-tuning models using proprietary company data. Standard software IP clauses don’t always cleanly cover model artifacts.
In regulated industries, add three more questions before your architecture is locked in: where can model inference happen (data residency)? Can the model’s decisions be audited (explainability)? Does sending data to OpenAI or Anthropic create GDPR or HIPAA exposure? These need legal review early, retrofitting compliance into a system that wasn’t designed for it typically costs more than building it in from the start.
Common Pitfalls of Building AI Development Team
This is the section most readers come for, so I thought it deserved more than a list of warnings. Each of these is a pattern we’ve seen damage real projects, with real timelines and budgets.
Hiring for Prestige Rather Than Fit
Here, I mean chasing PhDs or big tech alumni when what you need is someone practical who can ship.
Impressive credentials and the ability to build a production AI feature under real constraints are different skill sets. The most effective AI engineers we’ve worked alongside often have unconventional backgrounds. They’ve just shipped a lot of things and learned what breaks in production. Now, they are all set up to deliver business value.
Getting Into the Resume Trap
This one deserves its own moment, especially for non-technical founders.
The gap between a genuine ML Engineer and a junior developer who has connected the ChatGPT API a few times and learned the right vocabulary is enormous — in output quality, in architecture decisions, and in the problems they create downstream that someone else has to fix.
Imagine a founder hires someone who presents confidently as an AI architect. Three months later, the system is in production, but performance is poor, and the evaluation framework consists of manually eyeballing outputs.
Diagnosing and rebuilding that foundation costs more in time and money than hiring correctly would have in the first place. We’ve seen this add four to six months to a project timeline and $80,000–$150,000 in rework costs.
So, how can you protect yourself from cases like this?
My best advice would be to hire based on recommendations from people you know and trust. But is this is not an option in your case, then here are a few questions that might help you separate real experience from practiced vocabulary:
- How would they evaluate model performance on your specific use case?
- Whether they’ve worked with anything beyond fine-tuning or prompting, and what that looked like technically.
- Ask them to describe a failure they diagnosed in a production system: what broke, how they found it, and what the fix was.
These aren’t trick questions at all. They just require real experience to answer well. Someone who has only worked with demos and prototypes will either deflect or give textbook answers that don’t connect to an actual system.
Skipping Data Readiness
Building a model before your data pipelines are ready is the most common source of the “our AI doesn’t work” complaint. The model is rarely the problem.
The data — missing, inconsistent, inaccessible, or structured wrong for the use case — usually is. And data collection that happens after the architecture is designed almost always reveals that the data you have doesn’t match what the system was built to expect.
If your use case depends on internal company data, a Data Engineer needs to be your first hire or your first scoping conversation, not an afterthought after the ML Engineer has already designed an architecture around data that doesn’t exist yet.
Testing AI Like It’s Regular Software
Traditional QA checks whether buttons work and forms submit. AI tools need a different layer of evaluation entirely: Is the model hallucinating? What’s the precision and recall on the outputs that actually matter to your users? What’s the failure rate on edge cases specific to your domain?
This matters especially in systems where agents work with minimal human intervention. The less oversight there is in the loop, the more rigorous your evaluation framework needs to be. As code evolves and the system changes, you need to know whether the model’s behavior changed with it, which requires human judgment at key review points, not just automated checks.
Teams that only test the interface and never measure the model itself will have problems they can’t diagnose because everything looks fine until a user finds the failure. This is especially common with RAG systems, where retrieval quality degrades gradually and isn’t visible unless you’re measuring it.

The Hidden Costs of AI Development
This section could save you from a very uncomfortable conversation with your CFO six months from now. Why? Because the AI development cost structure is different from traditional software development in ways that aren’t obvious until you’re already inside the project.
The budget for an AI product has two distinct parts. Most teams plan carefully for one and get surprised by the other.
Part One: Team Costs (The Visible Part)
These are relatively predictable and easy to model out in advance.
Senior ML Engineers in most markets run between $150K–$220K annually, according to the recent data from Payscale. Experienced Data Engineers and AI-focused PMs sit in a similar range. MLOps and LLM Evaluators are increasingly in demand and priced accordingly.
For companies that consider offshore or nearshore options:
- senior ML Engineers in Eastern Europe typically run $80,000–$130,000 annually;
- in Latin America, $70,000–$120,000;
- in Southeast Asia, $50,000–$90,000.
These ranges are rough and vary significantly by country, seniority, and specialization, but the cost differential is real and worth modeling when comparing build-in-house against outsourced options. 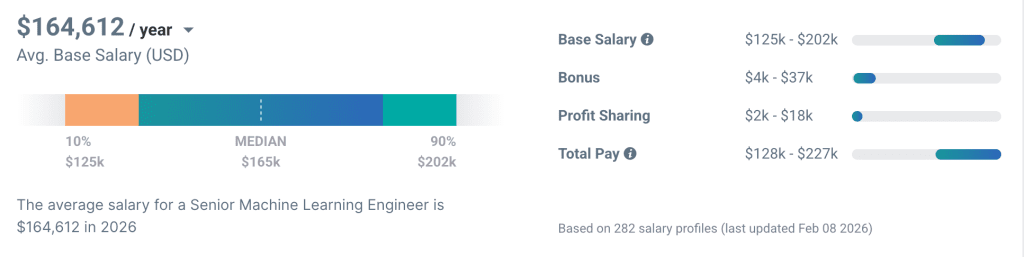
These costs are knowable ahead of time. You can build a hiring plan, attach numbers to it, and have a reasonable conversation about what it will take.
Infrastructure costs don’t work the same way.
Part Two: Infrastructure Costs (The Hidden Part)
This is where budgets quietly get away from teams, usually not all at once but gradually until someone pulls the monthly cloud bill and the number is genuinely shocking.
Cloud compute and GPU usage
Training runs and high-inference periods can spike significantly. A model that costs almost nothing to run during development can become meaningfully expensive when real users are hitting it continuously. GPU costs in particular are easy to underestimate if you haven’t run a production AI system before.
API token costs
Calling GPT-4, Claude, or Gemini at scale is not free, and token usage compounds quickly as you add features, increase context windows, or grow your user base. A product that makes one API call per user interaction behaves very differently at 100 users versus 10,000.
For reference:
| Usage level | Approximate monthly API cost* |
|---|---|
| Early testing / internal use | $50–$300 |
| Small user base (hundreds of users) | $500–$2,000 |
| Growing product (thousands of users) | $3,000–$15,000+ |
| Scale (tens of thousands of users) | $20,000–$100,000+ |
*These are rough illustrative ranges. Actual costs depend heavily on model choice, context length, and call frequency.
Vector database storage
Teams using RAG architectures accumulate embedding storage costs that grow with their data. Early on, this is negligible. As your knowledge base scales, it becomes a real line item that needs to be modeled and monitored.
Monitoring and observability tooling
Logging model behavior in production ( things like tracking outputs, flagging anomalies, measuring drift) requires tooling that adds another layer of ongoing cost. This is easy to forget during planning because it feels like infrastructure overhead rather than product cost. But without it, you’re flying blind, which carries its own kind of cost.
At the early stage of the software development process, infrastructure costs are manageable. But when you go into the scaling phase, when your data volume and user pool are growing, infrastructure costs can exceed team costs. This catches a lot of companies off guard.
The practical advice I would give here is to model out both buckets before you finalize your team structure or your architecture decisions.
Specifically, it’s worth estimating:
- Expected API call volume at different user scales.
- Average token usage per interaction.
- Compute requirements during peak inference periods.
- Storage growth rate for your knowledge base or embeddings.
A founder who knows these numbers in advance is in a fundamentally different position than one who discovers them mid-project.
How to Build an AI Development Team: A Practical Roadmap
Everything covered in this article leads to a practical question: where do you actually begin?
So, here’s a sequence of building an AI development team that tends to work from our experience:
1. Audit Your Data Situation
Before anything else, understand what data you have, where it lives, how clean it is, and whether it’s actually accessible in a usable format. This single step will shape every decision that follows: your architecture, AI development team needs, timeline, and your cost model.
If the data isn’t ready, getting it ready is the first project. Not the AI.
2. Define One High-Value Use Case
Resist the pull toward a broad AI strategy. Pick one specific, painful, high-frequency problem that AI could meaningfully address, and focus everything on that.
A focused first use case does several things at once: it keeps the team aligned, it gives you a clear success metric, and it produces something real that you can learn from. A broad AI initiative tends to produce activity without producing learning.
3. Decide Which Path You’re On
Using the framework from Section 1, make a deliberate decision about which path fits your situation. Don’t let this choice happen by default because someone on the team has a preference or a prior experience.
The path you choose determines the team you need, the infrastructure you’ll build, and the timeline you can realistically commit to.
4. Choose Your Build Approach
Based on your timeline, budget, and validated confidence in the use case, decide whether you’re building in-house, working with an external partner, or structuring a hybrid. Use the framework from Section 3.
If the concept is unvalidated and time matters, outsourcing to prove it first is usually the right call. If you’re scaling something proven, building internal capability makes more sense.

5. Map the Minimum Viable Team
Don’t staff to the full picture from day one. Based on your use case and your path, identify the smallest team that can build something real and get it in front of users.
For most API-path MVPs, that’s an ML Engineer, a Data Engineer, and a PM who understands AI well enough to make good trade-off decisions. Everything else can come later, once you know what “later” actually needs to look like.
6. Build Your Infrastructure Cost Model Alongside Your Hiring Plan
Estimate your API usage, your compute needs, and your storage growth. Stress-test those numbers at different scales. Make sure the economics of the product work before the team is assembled, and the architecture is locked in.
7. Plan for Iteration
Build checkpoints into the project. These are the moments where you evaluate what’s working, what isn’t, and what should change. Do not treat launch as the primary goal. AI products that improve are the ones where the team is structured to learn from what they ship, not just to ship it.

A Final Word About the AI Projects
A lot of companies feel like they’ve missed the window on artificial intelligence. They look at what competitors are announcing, what the headlines are saying, and conclude that the gap is too large to close.
The companies that are going to get the most from AI over the next few years aren’t necessarily the ones that started earliest. They’re the ones building with clarity: a real use case, the right team, honest expectations about what it takes, and a structure that lets them learn and iterate rather than just announce and move on.
Moving fast without that clarity doesn’t close the gap. It just burns the budget faster.
If you are looking for experienced AI developers that get the job done and comply with all data privacy and security laws, reach out for a quick consultation.


